Breizh Data Club
HISTOIRE DES DATA
Petite histoire des données en informatique et dans la vie en général
Introduction
En mathématiques, les données sont des quantités connues dans l’énoncé d’un problème et qui servent à trouver la solution. On parle alors des données d’un problème.
En informatique, on considère les données comme l’ensemble des indications enregistrées en machine afin de permettre l’analyse et/ou la recherche automatique des informations à partir de ces données. On parle ainsi de “jeu de donnnées”, de “base de données”, de “banque de données”, d’ “entrepôt de données”, de “données documentaires”, de “données lexicales”, de “données géolocalisées”, de “métadonnées”, etc. Tout cela pour alimenter un système d’information, un système informatique, une application logicielle, etc.
Une donnée est usuellement ce qui est connu a priori et qui sert de point de départ à un raisonnement ayant pour objet la détermination d’une solution à un problème en relation avec cette donnée. Une donnée peut être une description élémentaire qui vise à objectiver une réalité ou bien le résultat d’une mesure (i.e. une comparaison entre deux événements du même ordre). Ainsi, les données sont, en quelque sorte, des valeurs brutes d’observation et/ou elles proviennent d’une source de mesures. Idéalement, les données sont exprimées dans un format connu et codifié reconnu par une large communauté d’utilisateurs.
Par extension, les données peuvent être produites par une fonction, un système, un logiciel et/ou une machine. Ainsi les données en sortie (output data) d’un système peuvent devenir les données en entrée (input data) d’un autre système.
La donnée brute est dépourvue de tout raisonnement, supposition, constatation, probabilité. Elle est brute. Ainsi, elle peut servir de base à une recherche, à un processus d’étude ou de validation, à examen statistique, à un raffinage, etc.
La nature des données peut être très variée selon leur source : des chiffres, des lettres, des éléments complexes tels que des vecteurs ou des matrices, des ensembles structurés ou non-structurés, etc.
Jusqu’à récemment (disons quelques décennies), nous n’avions connaissance du monde réel qu’à travers la stimulation de nos sens naturels : vue, ouïe, odorat, goût et/ou toucher. Plus récemment, grâce à l’informatique, aux télécommunications, aux mesures physiques, à l’électronique et aux autres technologies numériques, nous avons pu déployer des systèmes capables de produire des données et de les traiter ensuite à la place des humains.
Avec le foisonnement des données, en informatique, on s’est alors mis à parler de Data Processing, de Data Base, d’Open Data, de Big Data, etc.
On n’accumule pas les données pour le plaisir. On le fait, en général, avec une intention ou un objectif. Par exemple, on veut en extraire des éléments statistiques, apprendre de nouvelles connaissances, aider un décideur à prendre des décisions ou automatiser des prises de décisions, activer des mécanismes robotisés, etc.
Pour simplifier, retenons une image : les données sont comme un minerai brut dont on peut extraire des informations après raffinage. Ces informations raffinées permettent ensuite de produire des connaissances plus ou moins élaborées sur la base desquelles on pourra prendre des décisions et, le cas échéant, déclencher des actions ciblées en fonction des connaissances élaborées.
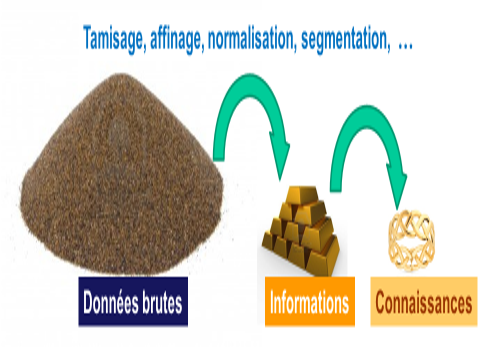

Fig.1 - Transformation graduelle des données en informations puis connaissances puis action
Au cours des dernières décennies, en raison notamment du développement des échanges induits par Internet, par le Web et par toutes les applications qui se sont greffées dessus, nous avons assisté à une inflation de la production de données. Cela a mécaniquement entrainé une profusion d’échanges de données et a contribué à nourrir encore plus le processus de transformation Données -> Informations -> Connaissances -> Décisions -> Actions.
D’énormes volumes de données proviennent notamment :
- des sciences d’observations et de mesures expérimentales : Astronomie, Météorologie, Climatologie, Nucléaire, Médecine et Epidémiologie, Démographie, Sociologie, Agronomie, etc.
- des techniques de visualisation et de partage d’information : Cartographie, Géomatique, Datavisualisation, etc.
- des réseaux d’objets connectés : véhicules terrestres, aériens ou navals, capteurs d’infrastructure réticulée, objets personnels (smartphones, …), etc.
- des réseaux sociaux (à titre individuel et/ou professionnel), etc.
- des fournisseurs de données ouvertes (Open Data)
- de l’observation automatisée des comportements des utilisateurs (et/ou clients) d’infrastructures : transports, collectivités publiques, réseaux d’eau, éléctricité, gaz, télécoms, etc.
- des robots, des automates et autres machines dotées de capteurs pour interagir avec leur environnement.
- Etc. Etc.
Actuellement, trois décennies après la création du Web, ce n’est plus la rareté des données qui limite leur exploitation. C’est plutôt la profusion des données qui rend parfois difficile leur analyse et leur valorisation. Il faut donc parfois faire des choix drastiques pour sérier les données et tenter d’en exploiter quelques sous-ensembles avec une pertinence accrue. C’est typiquement l’approche des tableaux de bord qui facilitent la visualisation des données afin de mieux décider et d’agir.
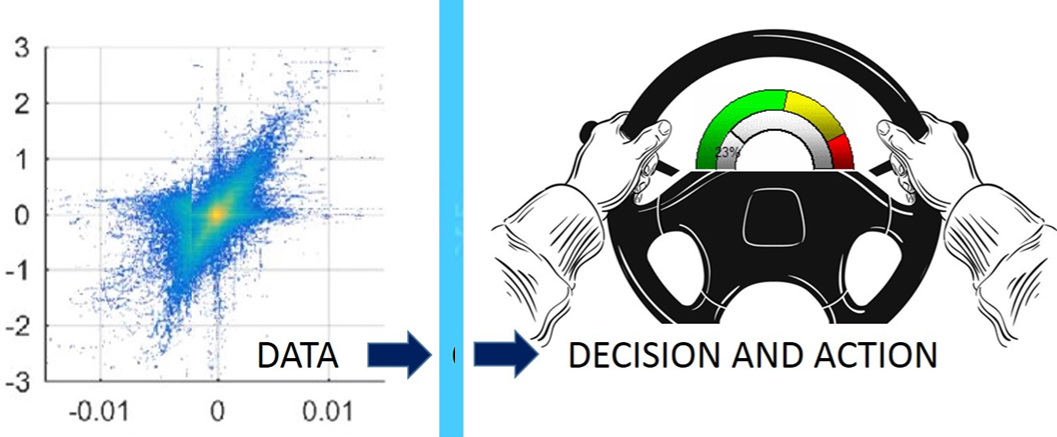
Fig.2 - Partir des données pour décider et agir
Quand on parle de Big Data (ou de Mégadonnées), on s’intéresse à des volumes considérables qui créent de nouveaus défis d’exploitation. Mais il n’y a pas de les volumes. Il faut également prendre en compte la vitesse de production des données et de leur traitement postérieur (en temps réel ou en temps différé). Et s’intéresser également à la variété (voire la variabilité) de ces données. En outre, on ne peut pas sous-estimer les questions de véracité et de valeur de ces données. En effet, à quoi servirait de faire des calculs gigantesques sur des données fausses ?
A quoi servent les données en informatique ?
Historiquement, dans les temps anciens de informatique, on ne considérait que le matériel. Normal ! Avant les années 1950, on parlait de mécanographie. C’est à dire de machines à calculer plus ou moins sophistiquées. Bien sûr, les machines à calculer travaillaient sur des données mais, bon, la plupart du temps les données étaient saisies à la main.
Par la suite, on s’est intéressé à la fois au matériel et au logiciel. Le logiciel (appelé “programme” à l’époque) consistait en une liste d’actions à réaliser sur le matériel. Cette liste d’actions rassemblait à la fois des algorithmes et des données plus ou moins entremélés. En gros, on considérait les données comme des constantes dans le code même du logiciel et, parfois, quand il fallait bien travailler sur quelques variables, on les alimentait à la main à l’aide d’un clavier, par exemple.
Quand les données ont commencé à devenir envahissantes, il a fallu inventer des processus de lecture externes pour nourrir les variables. On s’est alors intéressé au matériel, au logiciel et aux données. Ces dernières pouvaient être lues séquentiellement : sur des bandes perforées, sur des cartes perforées ou sur des claviers. Et même plus tard, sur des supports magnétiques (bandes, disques, etc.) ce qui a ouvert de nouvelles possibilités d’accès non-séquentiel. Un peu plus tard encore, le volume croissant des données a graduellement imposé l’idée de mieux structurer les données sous forme de tables, de listes, d’ensembles hétérogènes accessibles grâce à des index, etc.
Actuellement, en informatique, on s’intéresse au matériel, aux algorithmes, aux langages et aux données. Ce que l’on appelait “logiciel” est désormais scindé en deux sous-ensembles : d’un côté, ce qui relève des algorithmes (les méthodes pour faire, les recettes de cuisine en quelque sorte) et, d’autre part, les langages qui relèvent de l’implémentation concrète (les couches logicielles d’exploitation au dessus du matériel). Quant aux données, elles sont désormais accessibles en très grandes quantités et sous des formats extrêmement diversifiés. Certaines données sont publiques, d’autres proviennent de sources privées. Quelques unes sont hyperprotégées soit pour des raisons stratégiques (propriété intellectuelle ou autre), soit pour des raisons réglementaires (protection de la vie privée, etc.).
Quelles que soient leurs origines, les données sont désormais stockées ou produites en très grandes quantités. Pour faciliter leur utilisation et leur stockage, elles sont disponibles sous des formats sophistiqués visant à maximiser leur accessibilité en des temps les plus courts possible. Ainsi sont apparus divers formats de bases de données, de pipe-lines, d’ensembles multi-indexés, etc. destinés à stocker et brasser efficacement des mégadonnées (également appelées Big Data).
Aujourd’hui, les données sont partout. Dans la vraie vie et dans le monde de l’informatique en particulier.
Plus récemment, depuis les années 2010, la profusion gigantesque des données a facilité les techniques d’apprentissage automatique ce qui a favorisé le développement d’une nouvelle génération de robots dotés d’une certaine forme d’intelligence artificielle. Cette nouvelle perspective a ouvert de nouveaux chantiers : techniques, économiques, éthiques, juridiques,commerciaux, etc.
C’est ce qui explique pourquoi les données suscitent actuellement autant de passion (et donc autant de passionnés).
[|||||||||]
Pour en savoir plus sur ce thème
- Source 1 : CNRTL
- Source 2 : Wikipedia
- Source 3 : Histoire illustrée de l’informatique
Retour au sommaire
- Version 2024-04-25